Se ha comprobado que el tiempo de espera ( en minutos ) hasta ser atendido, en cierto servicio de urgencias, sigue un modelo normal de probabilidad. A partir de una muestra de 100 personas que fueron atendidas en dicho servicio, se ha calculado un tiempo medio de espera de 14,25 minutos y una desviación típica de 2,5 minutos. ¿Podríamos afirmar, con un nivel de significación del 5 % que el tiempo medio de espera, en este servicio de urgencias, no es de 15 minutos?
1. Se formula la hipótesis nula H0 y la hipótesis alternativa H1.
Hipótesis nula : H0 : μ = 15 Hipótesis alternativa : H1 : μ ≠ 15 Puesto que nuestra hipótesis nula está formulada en forma de igualdad, tenemos un contraste bilateral.
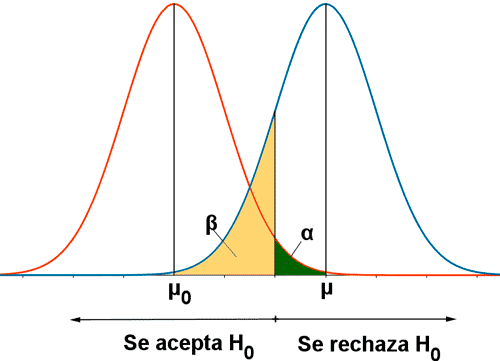
El error de tipo I también denominado error de tipo alfa (α) o falso positivo, es el error que se comete cuando el investigador no acepta la hipótesis nula siendo ésta verdadera en la población. Es equivalente a encontrar un resultado falso positivo, porque el investigador llega a la conclusión de que existe una diferencia entre las hipótesis cuando en realidad no existe. Se relaciona con el nivel de significancia estadística.
El error de tipo II también llamado error de tipo beta (β) o falso negativo, es el error que se comete cuando el investigador no rechaza la hipótesis nula siendo ésta falsa en la población. Es equivalente a la probabilidad de un resultado falso negativo, ya que el investigador llega a la conclusión de que ha sido incapaz de encontrar una diferencia que existe en la realidad.
Contrariamente al error tipo I, en la mayoría de los casos no es posible calcular la probabilidad del error tipo II. La razón de esto se encuentra en la manera en que se formulan las hipótesis en una prueba estadística. Mientras que la hipótesis nula representa siempre una afirmación enérgica.
Los errores tipo I y tipo II están relacionados. Una disminución en la probabilidad de uno por lo general tiene como resultado un aumento en la probabilidad del otro.
Un fabricante deseaba comparar la resistencia al desgaste de dos tipos distintos de neumáticos A y B. Para hacer la comparación, se asignó al azar un neumático del tipo A y uno del tipo B a las ruedas posteriores de 20 automóviles. Los coches recorrieron un número específico de kilómetros y se observó el desgaste de cada neumático. Automóvil 1 2 3 4 5 6 7 8 9 10 Neumático A 10.6 9.8 12.3 9.7 8.8 10 9.9 9 12.1 8.9 Neumático B 10.2 9.4 11.8 9.1 8.3 10.1 9.2 11.2 11 8.2 Automóvil 11 12 13 14 15 16 17 18 19 20 Neumático A 10.1 11 11.8 9.9 12.2 12.3 10.5 8.8 8.6 9.2 Neumático B 10.1 10 10.3 10.4 11.1 11.3 9.3 8.5 10.3 11 ¿ Presentan los datos suficiente evidencia para concluir que hay diferencia en el desgaste promedio de los dos tipos de neumáticos? Dentro de Excel los datos para su análisis han sido ordenados en columnas, como se muestra a continuación.. El procedimiento para solicitar en Excel la prueba de medias para este caso es el siguiente: Seleccione del menú principal Herramientas/...
Una operación de ensamblaje de una planta industrial requiere que un empleado nuevo se someta a un período de entrenamiento para alcanzar su máxima eficacia. Se sugirió un nuevo método de entrenamiento y se llevó a cabo de una prueba para comparar los métodos. Dos grupos de nueve empleados nuevos se entrenaron durante un período de tres semanas, un grupo usando el nuevo método y el otro siguiendo el procedimiento de entrenamiento estándar. Al final del período de tres semanas se observó el tiempo en minutos que le tomó a cada empleado ensamblar el dispositivo. ¿Presentan los datos suficiente evidencia que indique que el tiempo medio de ensamblaje al final del período de entrenamiento de tres semanas es menor para el nuevo método? Procedimiento estándar Procedimiento nuevo 32 35 37 31 35 29 28 25 41 34 44 40 35 27 31 32 34 31 Dentro de Excel los datos para su análisis han sido ordenados en columnas, como se muestra a continuación. El procedimiento para solicitar en Excel la prueba de me...
Prueba t de Student para muestras independientes Supongamos que tenemos dos muestras aleatorias e independientes con medias de ¯ x 1 x 1 ¯ y ¯ x 2 x 2 ¯ y que queremos saber si estas dos medias son signifacativamente distintas a un nivel de p ⩽ 0 , 05 p ⩽ 0 , 05 . Esto es lo mismo que decir que si afirmamos que hay una diferencia entre las muestras tenemos un 95% de probabilidad de tener razón. Lo que tenemos que calcular, entonces, es la probabilidad de que las dos muestras pueder provenir de la misma distribución y que la diferencia que vemos es por varianza en esa población. En otras palabras: queremos saber si dos muestras con la diferencia observada ( ¯ x 1 − ¯ x 2 x 1 ¯ − x 2 ¯ ) podrían tener provenir de la misma población. Si sacamos un número significativo de muestras de una misma población la media de estas muestra va a tener una diferencia con la media de la población, en algunos casos más altos y en otros más bajos. Usamos este conocimiento para...
Comentarios
Publicar un comentario